A Parameter-Efficient Approach to Distilling Large Language Models via Meta-Learning
Sep 23, 2025·,,·
0 min read
Riccardo Cantini
Nicola Gabriele
Alessio Orsino
Abstract
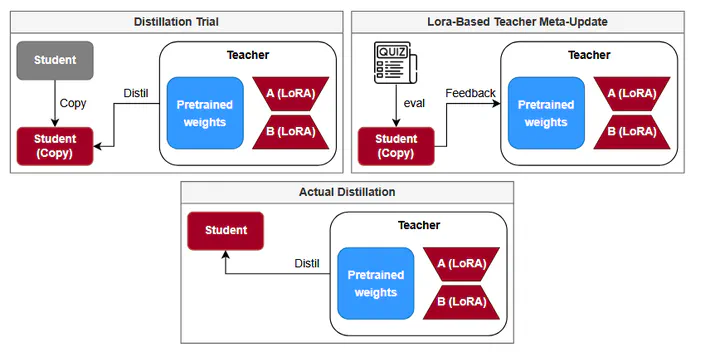
Large Language Models (LLMs) have revolutionized artificial intelligence, significantly improving performance in tasks such as machine translation, summarization, and conversational systems. These models, however, typically consist of hundreds of millions or even billions of parameters, making them computationally expensive to train and deploy. This presents a major challenge, especially when considering the growing demand to integrate such models into resource-constrained environments like mobile devices or embedded systems. To address this issue, model compression techniques have become essential, such as Knowledge Distillation, which aims to transfer knowledge from a complex model—referred to as the teacher—to a more compact, computationally efficient one—known as the student—without significantly compromising performance. Moreover, recent studies have shown that meta-learning techniques, particularly extit{learning-to-teach} frameworks, can enhance the distillation process. However, while knowledge distillation via meta-learning is especially effective under high compression ratios, it involves a computationally intensive training process to optimize the teacher’s parameters for effective knowledge transfer, leading to substantial resource and energy consumption. To address this issue, we propose a resource-efficient distillation framework that integrates meta-learning with Parameter-Efficient Fine-Tuning (PEFT) techniques, leveraging Low-Rank Adaptation (LoRA) for the teacher’s meta-update. By minimizing the computational and memory demands of the distillation process, our approach reduces energy consumption without compromising model performance, ultimately enabling more sustainable AI systems.
Publication
CAIMA2025 workshop, part of the ADBIS2025 conference (September 23-26, 2025 - Tampere)